
在 AWS 上通過數據分類節省成本
AWS

雲成為許多組織的一個大的成本中心。雖然雲服務經常被宣傳為節省成本的方式——而且許多雲遷移是由希望節省 IT 成本的願望驅動的——雲服務同時也創造了運營開銷,同時減少了資本開銷。此外,與傳統的 IT 投資不同,雲成本可能是不可預測的,並且很快就會失控。
然而,雖然雲創造了問題,它也提供了解決問題的工具。例如,在 AWS 上,成本的主要組成部分之一是通過備受尊敬的 Simple Storage Service (S3) 提供的對象存儲。S3 是現代數據湖、大規模媒體庫、網站內容、非結構化內容庫等的基礎。
幸運的是,S3 提供了一種存儲分層機制,可以顯著降低不常用內容的成本。要有效利用存儲分層,您需要採用數據分類的概念——自動發現您不常訪問的數據並將其動態移動到最合適的存儲層。
什麼是數據分類?
數據分類一詞指的是將非結構化和結構化數據組織到代表不同數據類型的類別中的做法。
數據分類是一種組織實踐,可以幫助您實現兩個關鍵目標:
- 了解您存儲了哪些類型的數據
- 確定每種數據類型的位置
以下是 Gartner 定義的幾個數據分類用例:
- 控制知識產權(IP)——數據分類幫助您控制對數據的訪問並定義適當的位置。
- 減少攻擊面——您可以使用數據分類在存儲敏感數據的位置減少攻擊面。
- 識別受法規管制的數據——數據分類使您能夠將數據歸類到特定的合規類別中,確保您滿足 GDPR、HIPAA 和 PCI DSS 等相關法規設定的要求。
- 提供內容訪問——使用數據分類根據數據類型、使用等配置訪問。
- 移除數據冗餘——使用數據分類識別並移除冗餘或過時的數據。
- 優化業務活動——數據分類可以幫助您設置元數據標籤,以優化不同的業務活動。
- 了解您的數據模式——發現有關數據使用和位置的信息。
什麼是 Amazon S3 智能分層?
S3 智能分層是一種雲存儲類別,它監控訪問模式以確定每個對象的最佳存儲層。它自動將訪問較少的對象轉移到成本較低的訪問層。
存儲分層是節省雲成本的關鍵策略。智能分層(Intelligent-Tiering)是一種自動化的存儲分層機制,當數據訪問模式發生變化時,可以在不影響性能或創造運營開銷的情況下節省存儲成本。
Amazon S3 智能分層的關鍵用例包括:
- 擁有變化訪問模式的數據——不可預測、變化或未知的訪問模式,不依賴於保留期或對象大小。
- 不常修改的數據——對於不經常修改的幾乎任何工作負載,尤其是數據分析、數據湖和用戶生成內容(UGC),可以將此存儲類別用作默認選項。
請注意,S3 智能分層除了常規的 S3 GB/月存儲成本和與每個存儲層相關的數據轉移費用外,還會有額外的每 GB/月成本。
如何運作 S3 智能分層
S3 智能分層基於機器學習算法監控和預測用戶行為,將存儲數據分配到適當的訪問層。這些算法基於在 S3 存儲的數以萬億計的對象的數據流量模式進行訓練。智能分層允許在細粒度對象級別上進行管理,當其訪問模式變化時將每個對象移動到不同的存儲層。
如果一個對象在 30 天內沒有被訪問,S3 智能分層會自動將其轉移到不常訪問訪問層。如果您在 90 天內沒有訪問某些對象,AWS 會將它們移動到即時訪問存檔層。為了實現更低的存儲成本,您可以選擇使用可以在幾分鐘或幾小時內訪問的存檔層。
如何使用 S3 智能分層削減成本
S3 智能分層存儲系統使用自動存儲類別優化來最小化存儲成本。Amazon S3 API、AWS CLI 和 AWS 管理控制台允許您設置 S3 智能分層以自動存檔異步訪問的數據。
如何將數據移動到 S3 智能分層
您可以使用 PUT 請求直接將數據轉移至 S3 智能分層。或者,您可以設置 S3 生命周期策略,將對象從標準 S3 存儲類別移動到 S3 智能分層。
要直接使用 PUT 操作將數據上傳到 S3 智能分層,請在 x-amz-storage-class 標頭中指定 Intelligent-Tiering。例如,以下 PUT 請求使用智能分層將圖像存儲在 S3 桶中:
PUT /image-for-classification.jpg HTTP/1.1
Host: myBucket.s3.<Region>.amazonaws.com
Date: Fri, 7 Jan 2021 18:15:00 GMT
Authorization: <your-authorization-string>
Content-Type: image/png
Content-Length: 15342
Expect: 100-continue
x-amz-storage-class: INTELLIGENT_TIERING如何啟用 S3 智能分層存檔層
存檔層(例如,存取存檔層、深度存檔存取層)允許您以低成本存儲數據並在幾分鐘或幾小時內訪問它。您可以使用管理控制台 CLI 或 S3 API 創建一個桶、對象標籤級配置或前綴來激活存檔訪問層(或兩者)。您可以通過 AWS 管理控制台、Amazon S3 API 或 AWS CLI 創建桶、前綴或對象標籤級配置來激活一個或兩個存檔訪問層。
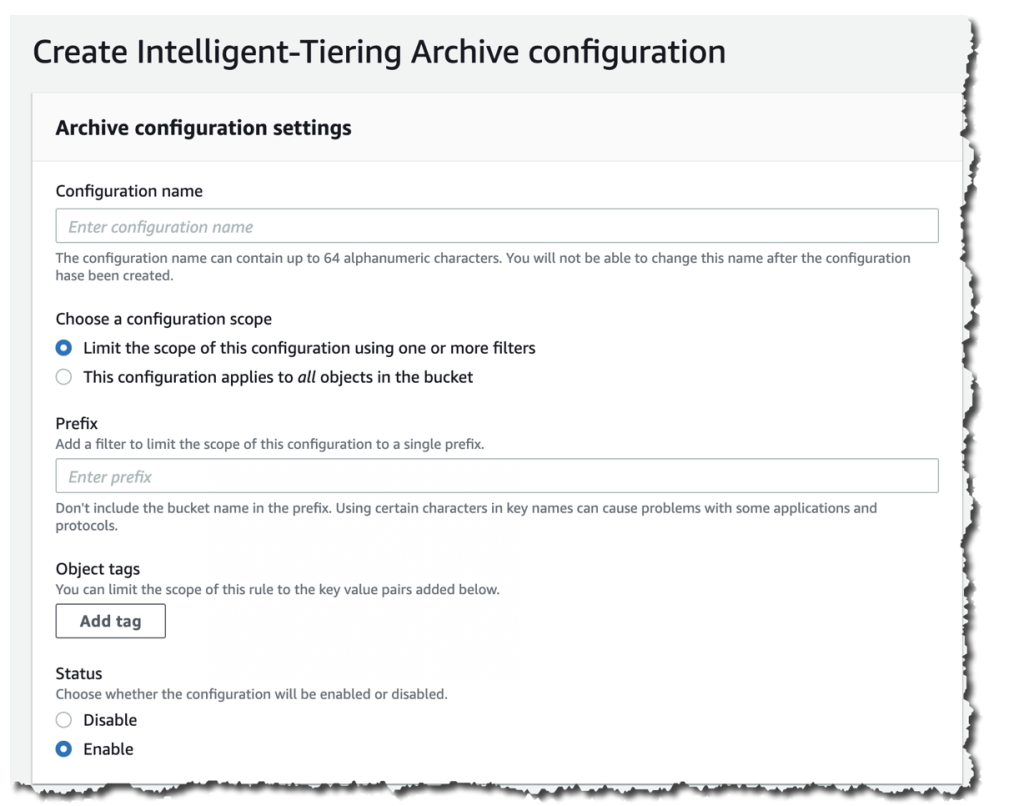
通過 S3 控制台啟用 S3 智能分層的自動存檔:
- 通過選擇“限制此配置的範圍與一個或多個過濾器”來限制配置範圍。
- 在“前綴”下,指定單個前綴以定義配置範圍。
- 要使用對象標籤來定義配置範圍,選擇“添加標籤”並在“鍵”下指定值。
- 在“狀態”下選擇“啟用”。
- 轉到“存檔設置”,選擇您想要啟用的存取存檔層。您可以選擇兩者。
- 選擇“創建”以設置配置。
- 透過這些步驟,您可以有效啟用 S3 智能分層的自動存檔功能,這將幫助您對不常訪問的數據進行更經濟高效的存儲管理,從而節省存儲成本。
- 選擇“創建”以設定配置。
結論
在這篇文章中,我展示了如何通過 Amazon S3 智能分層機制,具體應用數據分類概念來顯著降低 AWS 上的存儲成本。這只是一個由數據分類和機器學習驅動的雲成本節省的例子,您可以將其擴展到雲部署的其他部分:
- 利用像 Amazon Macie 這樣的 AI 分析服務來識別敏感數據,如個人識別信息(PII),並將其移動到最合適的存儲介質或存儲層。
- 使用像 Amazon Trusted Advisor 這樣的工具來自動識別未使用或利用不足的雲資源——如塊存儲卷和快照。
- 將您的分析擴展到包括本地環境和其他雲中——以確定哪種環境最適合您的數據。
希望這對您在雲中提高對存儲成本的可見性和控制力有所幫助。

